
Did LLMs kill anonymity?
no proof

This paper just dropped. Some ETH Zurich researchers built an AI pipeline that managed to classify 68% of HN users’ real identities based on their posts — at only 1-4$ per profile:
We show that large language models can be used to perform at-scale deanonymization. With full Internet access, our agent can re-identify Hacker News users and Anthropic Interviewer participants at high precision, given pseudonymous online profiles and conversations alone, matching what would take hours for a dedicated human investigator. We then design attacks for the closed-world setting. Given two databases of pseudonymous individuals, each containing unstructured text written by or about that individual, we implement a scalable attack pipeline that uses LLMs to: (1) extract identity-relevant features, (2) search for candidate matches via semantic embeddings, and (3) reason over top candidates to verify matches and reduce false positives. Compared to prior deanonymization work (e.g., on the Netflix prize) that required structured data or manual feature engineering, our approach works directly on raw user content across arbitrary platforms. We construct three datasets with known ground-truth data to evaluate our attacks. The first links Hacker News to LinkedIn profiles, using cross-platform references that appear in the profiles. Our second dataset matches users across Reddit movie discussion communities; and the third splits a single user's Reddit history in time to create two pseudonymous profiles to be matched. In each setting, LLM-based methods substantially outperform classical baselines, achieving up to 68% recall at 90% precision compared to near 0% for the best non-LLM method. Our results show that the practical obscurity protecting pseudonymous users online no longer holds and that threat models for online privacy need to be reconsidered.
This is their pipeline:
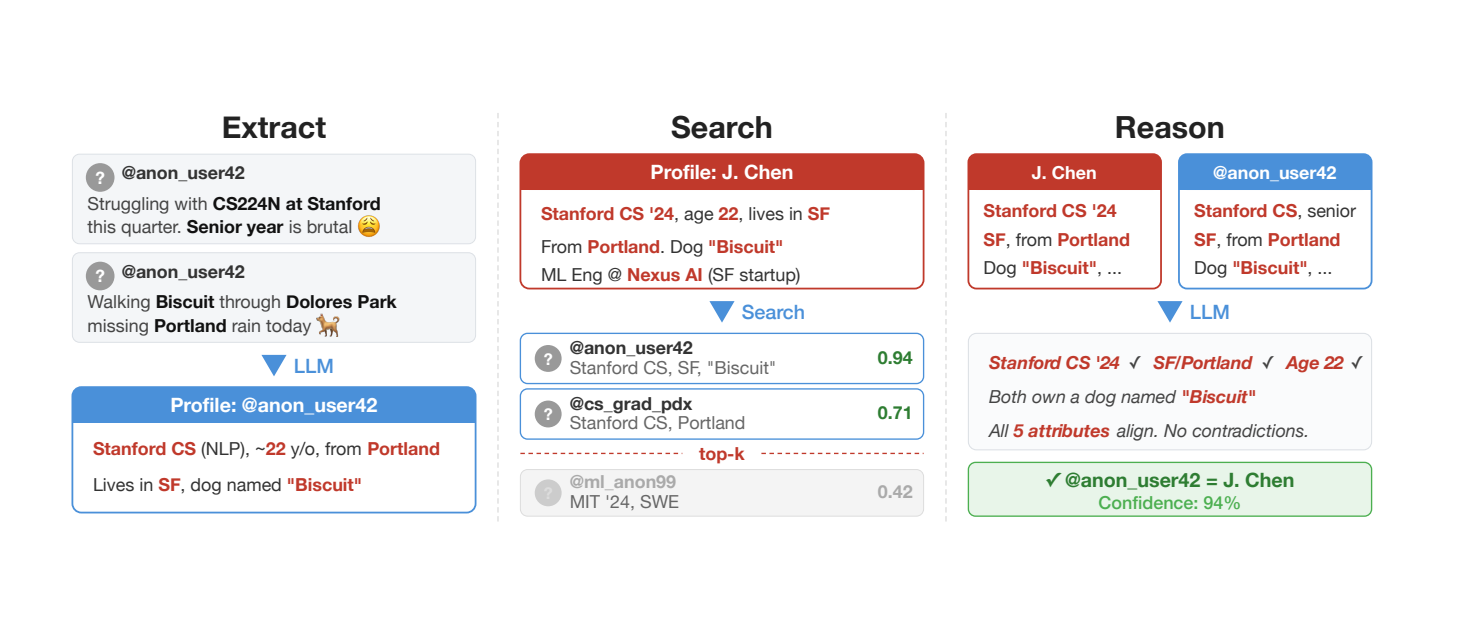
There’s a catch, of course. The set of users they selected were ones who already had linkedin profiles attached — but they removed the profile + links from the data before they ran them through the classifier. So the analysis isn’t contaminated, but it is vulnerable to selection bias: people with linkedin profiles in their bios are certainly much more likely to disclose other information in their posts.
Hacker News → LinkedIn. We collect 338 Hacker News (HN) users who linked a LinkedIn profile in their publiclyvisible HN bio, providing verified real-world identities as ground truth. We first summarize each user’s HN activity (comments and stories) into a structured profile. Then we create a search prompt and anonymize it (see Appendix A for details), and pass it to the agent. The agent correctly identifies 226 of 338 targets (67%) at 90% precision (95% CI: 86–93%; 25 incorrect identifications, 86 abstentions).
When the model sorted through 125 interviews with scientists, it could only identify 9 of the 33 (33, presumably because they didn’t pass in all 125) subjects from the interview:
Anthropic Interviewer transcripts. Anthropic publicly released transcripts of 125 AI-conducted interviews with scientists [2, 15], in which participants described their use of AI in their research. The transcripts were partially redacted for participant privacy. Li [19] showed that LLM agents with web search can match project descriptions in these transcripts to published papers; specifically, they use a task decomposition approach [17] to bypass safeguards by breaking the attack down into individual benign tasks. They eventually ran their attack on 24 scientists conversations and recovered 6 identities. We attack the same dataset with our pipeline, without task decomposition. Concretely, we construct profiles from transcripts in a similar way as we do for Hacker News and Reddit users; and then run the agentic search on 33 scientists that talked about their past research in the transcripts. The agent correctly identifies 9 out of 33 scientists at 82% precision (2 wrong, 22 refusals or abstentions). Here, we are uncertain about the true deanonymization rate, as we have to manually verify the matches. The agent claims to identify 11 scientists; but for 2 out of 11 we notice the transcript contradicts the identified academic profile in some ways.
Will anonymity die?
Probably, at some point. Not through AI agents, in my opinion, which will get easily confused by misdirection, but through data leaks. So much gets leaked every year that, at some point, people are going to start using them to dox people on the internet.
I always found the anonymity debate uninteresting, since the solution I support (your name is whatever you want it to be) is the status quo, I also view this preferred solution as contingent and unstable, so I’m not that invested in it staying that way, though I will be sad to see anonymity go.
If anonymity really does die, then we will find ourselves in an odd place where the only people willing to say interesting stuff on the internet are old, have nothing to lose, are wealthy, and/or are impulsive. Which will be unfortunate for the rest of us, of course, but I’m not convinced that will kill contrarian/anti-establishment sentiment and communities on the internet.
Good post. To combat this you'll probably need to start "speaking thru LLMs" on the internet if you wanna remain anon. You send the comment you want to send to some LLM, it rewrites it and whitewashes it, and then you post this LLM-ified comment or post, wherever you desire.
Seperate topic, but you can upload photos to LLMs (after stripping all the metadata, turn off location, etc) and they are incredible at predicting the location you are in. Just with like types of trees, buildings, shadow length, god knows what else. So similar-ish problem here if you are a anon and posting any sort of image really.
Thank you, that post on HN was awful, as was the fact that the only comment spotting it was buried at the bottom and attacked by the site owner.